 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)

[多选]
假设线性回归模型满足全部根本假设,那么其参数的估计量具备()。
A、可靠性
B、合理性
C、线性
D、无偏性
E、有效性
暂无答案
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
A、可靠性
B、合理性
C、线性
D、无偏性
E、有效性
 更多“假设线性回归模型满足全部根本假设,那么其参数的估…”相关的问题
更多“假设线性回归模型满足全部根本假设,那么其参数的估…”相关的问题
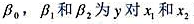 回归的OLS估计量。(给定样本中自变量的值)证明β1的期望值是
回归的OLS估计量。(给定样本中自变量的值)证明β1的期望值是
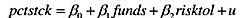 满足前四个高斯-马尔科夫假定,其中,petstck表示工人养老金投资于股票市场的百分比,funds表示工人可以选择的共同基金的个数,而risktol表示对风险承受能力的某种度量(rsktol越大,则表明这个人对风险的承受能力越强)。如果funds和risktol正相关,pctstck对funds简单回归的斜率系数有怎样的不一致性?
满足前四个高斯-马尔科夫假定,其中,petstck表示工人养老金投资于股票市场的百分比,funds表示工人可以选择的共同基金的个数,而risktol表示对风险承受能力的某种度量(rsktol越大,则表明这个人对风险的承受能力越强)。如果funds和risktol正相关,pctstck对funds简单回归的斜率系数有怎样的不一致性?A、随机误差项是一个期望值为0的随机变量
B、对于解释变量的所有观测值,随机误差项有相同的方差
C、随机误差项彼此相关
D、解释变量是确定性变量不是随机变量,与随机误差项之间相互独立
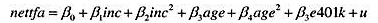
 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。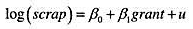
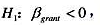 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?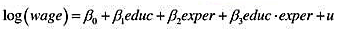










 如果结果不匹配,请
如果结果不匹配,请 