 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)

[主观]
给定二元回归模型:yt=b0+b1x1t+b2x2t+ut,请表达模型的古典假定。
暂无答案
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
 更多“给定二元回归模型:yt=b0+b1x1t+b2x…”相关的问题
更多“给定二元回归模型:yt=b0+b1x1t+b2x…”相关的问题
当多元线性回归模型进行f检验时,发现f统计量大于给定的显著性水平下,对应的临界值说明()。
A、模型中所有的自变量对因变量的影响均显著
B、模型总体显著
C、模型中所有的自变量对因变量的影响不显著
D、模型总体不显著
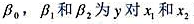 回归的OLS估计量。(给定样本中自变量的值)证明β1的期望值是
回归的OLS估计量。(给定样本中自变量的值)证明β1的期望值是
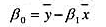 。
。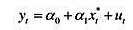
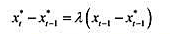
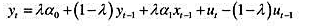
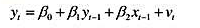
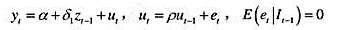

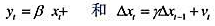 其中,
其中,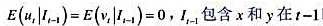 时期及此前的所有信息β≠0,且|y|<1[于是xt并因而yt是((1)]。证明:这两个方程意味着如下形式的一个误差修正模型:
时期及此前的所有信息β≠0,且|y|<1[于是xt并因而yt是((1)]。证明:这两个方程意味着如下形式的一个误差修正模型: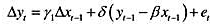
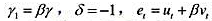 。(提示:首先从第一个方程的两边减去yt-1.然后在右边加上并减去一个βxt-1,并重新整理。最后,利用第二个方程得到包含Δxt-1的误差修正模型。)
。(提示:首先从第一个方程的两边减去yt-1.然后在右边加上并减去一个βxt-1,并重新整理。最后,利用第二个方程得到包含Δxt-1的误差修正模型。)
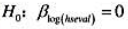 的双侧p值。
的双侧p值。










 如果结果不匹配,请
如果结果不匹配,请 